
It's also possible to use random number generation to enact decisions that are still arbitrary but are somewhat more predictable than plain randomness. One can apply a probability factor to make one choice more likely than another in a binary decision, or (as will be demonstrated in a future lesson) one can apply a more complicated probability function to a set of possibilities, giving each one a different likelihood. This lesson will demonstrate the first case, using a probability factor to make a binary decision in which one result is more likely to occur than the other.
As described briefly in an earlier lesson on randomness, the probability of a particular looked-for event occurring can be defined as a number between 0 and 1 inclusive, with that number being the ratio of the number of looked-for outcomes divided by the number of all possible outcomes. For example, the probability of choosing the the ace of spades (1 unique looked-for result) out of all possible cards in a deck (52 of them) is 1/52, which is 0.019231. The probability of not choosing the ace of spades is 1 minus that, which is 0.980769 (51/52). Thus we can say that the likelihood of choosing the ace of spades at random from a deck of cards is less than 2%, and the likelihood of not choosing it is a bit more than 98%; other ways of stating this are to say that there is a 1 in 52 chance of getting the ace of spades, or to say that the odds against choosing the ace of spades are 51 to 1.
For making an automated decision between two things, we can emulate this sort of odds by applying a probability factor between 0 and 1 to one of the choices. For example, if we want to make a decision between A and B, with both being equally likely, we would set the probability of A to 0.5 (and thus the probability of B would implicitly be 1 minus 0.5, which also equals 0.5). If we want to make A somewhat more likely than B, we could set the probability of A to something greater than 0.5, such as 0.75. This would mean there is a 75% chance of choosing A, and a 25% chance of choosing B; the odds in favor of choosing A are 3 to 1 (75:25). This does not ensure that A will always be chosen exactly thrice as many times as B. It does mean, however, that as the number of choices increases, statistically the percentage of A choices will tend toward being three times that of B.
The simplest way to do this in a computer program is as follows: Set the probability P for choice A. Choose a random number x between 0 and 1 (more specifically, 0 to just less than 1). If x is less than P, then choose A; otherwise, choose B. The result of such a program will be that over the course of numerous choices, the distribution of A choices over the total number of choices will tend toward P. The choices will still be arbitrary, and we can't predict any individual choice with certainty (unless the probability of A is either 0 or 1), but we can characterize the statistical probability of choosing A or B.
Because the random generator in Max produces whole numbers less than the specified maximum rather than fractional numbers between 0 and 1, we have to do one additional step: we either have to map the range of random numbers into the fractional 0-to-1 range, or we have to map the probability factor into the range of whole numbers. It turns out to be slightly more efficient to do the latter, because it requires doing just one multiplication when we specify the probability, rather than doing a division every time we generate a random number. The following tiny program does just that. Every time it receives a message in its inlet, it will make a probabilistic choice between two possible results, based on a provided probability factor.
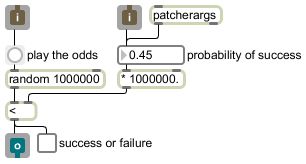 The probability value that goes into the number box (either by entering the number directly or by it coming from the right inlet or the patcherargs obejct) gets multiplied by 1,000,000 and the result is stored in the right inlet of the less than object. The bang from the button (triggered either by a mouse click or by a message coming in the left inlet) causes random to generate a random number from 0 to 999,999. If it is less than the number that came from the probability factor (which would be 450,000 in the above example), it sends out a 1, otherwise it sends out a 0. You can see that statistically, over the course of many repetitions, it will tend to send out 1 about 45% of the time.
The probability value that goes into the number box (either by entering the number directly or by it coming from the right inlet or the patcherargs obejct) gets multiplied by 1,000,000 and the result is stored in the right inlet of the less than object. The bang from the button (triggered either by a mouse click or by a message coming in the left inlet) causes random to generate a random number from 0 to 999,999. If it is less than the number that came from the probability factor (which would be 450,000 in the above example), it sends out a 1, otherwise it sends out a 0. You can see that statistically, over the course of many repetitions, it will tend to send out 1 about 45% of the time.A useful programming trick that is invisible in this picture is that the number box has been set to have a minimum value of 0 and a maximum value of 1. Any value that comes in its inlet will be clipped to that range before being sent out, so the number box actually serves to limit the range and prevent any inappropriate probability values that might cause the program to malfunction. Protecting against expected or unwanted values, either from a user or from another part of the program, is good safe programming practice.
As was mentioned earlier, the multiplication of the probability by 1,000,000 is because we want to express the probability as a fraction from 0 to 1, but random only generates random whole numbers, so we need to reconcile those two ranges. We chose the number 1,000,000 because that means that we can express the probability to as many as six decimal places, and when we multiply it by 1,000,000 the result will always be a unique integer representing one of those 1,000,001 possible values (from 0.000000 to 1.000000 inclusive). Since six decimal places is the greatest precision that can be entered into a standard Max object, this program takes full advantage of the precision available in Max. It's inconceivable that you could create a situation in which you could ever hear the difference between a 0.749999 probability and a 0.750000 probability (indeed, in most musical situations it's doubtful you could even hear the difference between a 0.74 probability and a 0.75 probability), but there's no reason not to take advantage of that available precision.
Notice that this little program has been written in such a way that it can be tried out with the user interface objects number box, button, and toggle, but it was actually designed to be useful as a subpatch in some other patch, thanks to the inclusion of the inlet, outlet, and patcherargs objects. All of its input and output is actually expected to come from and go to someplace else in the parent patch, for use in a larger program. The number box clips any probability value to the 0-to-1 range, and the button converts any message in the left inlet to a bang for random. Save this patch with the name gamble, because it is used in the next example patch.
Now that we have a program that reliably makes a probabilistic decision, we'll use it to make a simple binary decision whether to play a note or not.
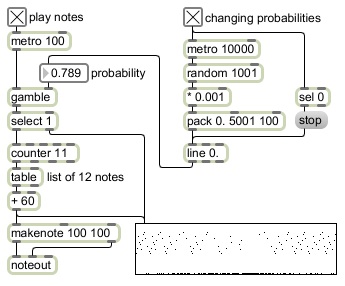 If the metro 100 object were connected directly to the counter 11 object, the patch would repeatedly count from 0 to 11, to cycle through a list of twelve pitch classes stored in the table, to play a loop at the rate of ten notes per second. However, as it is, the metro 100 object triggers the gamble object to make a probabilistic decision, 1 or 0. The select 1 object triggers a note only if the choice made by gamble is 1. If you click on the toggle to turn on the metro 100 object you will initially hear nothing because the probability of gamble choosing a 1 is set to 0. If you change the probability value to 1., gamble will always choose 1, and you will hear all the notes being played.
If the metro 100 object were connected directly to the counter 11 object, the patch would repeatedly count from 0 to 11, to cycle through a list of twelve pitch classes stored in the table, to play a loop at the rate of ten notes per second. However, as it is, the metro 100 object triggers the gamble object to make a probabilistic decision, 1 or 0. The select 1 object triggers a note only if the choice made by gamble is 1. If you click on the toggle to turn on the metro 100 object you will initially hear nothing because the probability of gamble choosing a 1 is set to 0. If you change the probability value to 1., gamble will always choose 1, and you will hear all the notes being played. If the probability is set to some value in between 0 and 1, say 0.8, gamble will, on average, choose to play a note 80% of the time and choose to rest 20% of the time. The exact rhythm is unpredictable, but the average density of notes per second will be 8.
If the probability is set to some value in between 0 and 1, say 0.8, gamble will, on average, choose to play a note 80% of the time and choose to rest 20% of the time. The exact rhythm is unpredictable, but the average density of notes per second will be 8.The upper right part of the patch randomly chooses a new probability somewhere in the range from 0 to 1 every ten seconds, and uses linear interpolation to arrive at the newly chosen probability value in five seconds. The probability will then stay at that new value for five seconds before the next value is chosen. By turning on this control portion of the patch, you can hear the effect of different statistical note densities in time, and the gradual transition from one density to another over five seconds.
Note that when gamble chooses 0, no note is played but the select 1 object still sends the 0 to the multislider (but not to the counter) so that the musical rest is shown in the graphic display, creating the proper depiction of the note density.
In this lesson we made a useful subpatch for making probabilistic decisions, and we used those decisions to choose whether to play a note or not. Of course the decision could be between any two things. For example you might use it to make control decisions, at a slower rate, choosing whether to run one part of the program or another, to control a longer-term formal structure.
No comments:
Post a Comment