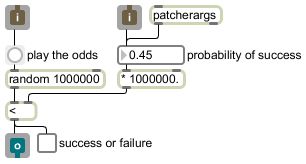
This is fairly straightforward to implement as a computer program, and the process for choosing from a discrete probability distribution of multiple possibilities is essentially the same as choosing from a set of two possibilities. If we know the sum of the probabilities, we can in effect divide that range into multiple smaller ranges, the sizes of which correspond to the probability for each one of the possibilities. We can then choose a random number less than the sum, and check to see in which sub-range it falls. The process is something like this:
1. Construct a probability vector.
2. Calculate the sum of all probabilities.
3. Choose a random (nonnegative) number less than the sum.
4. Begin cumulatively adding individual probability values, checking after each addition to see if it has resulted in a value greater than the randomly chosen number.
5. When the randomly chosen value has been exceeded, choose the event that corresponds to the most recently added probability.
Here's an example. If we have six possible events {a, b, c, d, e, f} with corresponding probabilities {0., 0.15, 0., 0.25, 0.5, 0.1} and we choose a nonnegative random number less than their sum (the sum of those probabilities is 1.0) -- let's say it's 0.62 -- we then begin cumulatively adding up the probability values in the vector till we get a number greater than 0.62. Is 0. greater than 0.62? No. Is 0.+0.15=0.15 greater than 0.62? No. Is 0.15+0.=0.15 greater than 0.62? No. Is 0.15+0.25=0.4 greater than 0.62? No. Is 0.4+0.5=0.9 greater than 0.62? Yes. So we choose the event that corresponds to that last probability value: event e. It is clear that by this method events a and c can never be chosen. Random numbers less than 0.15 will result in b being chosen, random numbers less than 0.4 but not less than 0.15 will result in d being chosen, random numbers less than 0.9 but not less than 0.4 will result in e being chosen, and random numbers less than 1.0 but not less than 0.9 will result in f being chosen. In short, the likelihood of each event being chosen corresponds to the probability assigned to it.
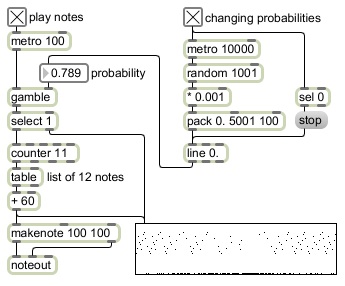
Max has an object designed for entering a probability vector and using it to make this sort of probabilistic decision. Interestingly, it is the same object we've been using for storing other sorts of arrays: the table object. When the table object receives a bang in its left inlet, it treats its stored values as a probability vector (instead of as a lookup array), uses that vector to make a probabilistic choice, and sends out the index (not the value itself) that corresponds to the choice, as determined by the process described above.
Note that this is fundamentally different from the use of table described in an earlier lesson, to look up values in an array. It's also fundamentally different from randomly choosing one of the values in an array by choosing a random index number. In this case, we're using the index numbers in the table (i.e., the numbers on the x axis) to denote different possible events, and the values stored in the table (i.e. the numbers on the y axis) are the relative probabilities of each event being chosen. A bang message received by the table object tells it to enact this behavior.
Note also that the probability values in the table don't need to add up to 1.0. In fact, that would be completely impractical since table can only hold integer values, not fractional ones. The probabilities can be described according to any desired scale of (nonnegative) whole numbers, and can add up to anything. The table object just uses their sum (as described in step 2 of the process above) to limit its choice of random numbers.
This program demonstrates the use of probability distributions to choose from among six possible pitches and six possible colors, with different likelihoods.
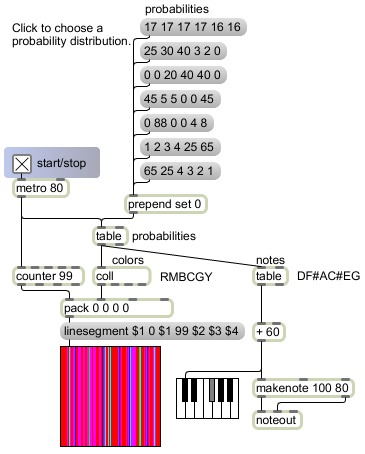
The table labeled "probabilities" stores a probability distribution. Its contents can set be set to one of seven predetermined distributions stored in the message boxes labeled "probabilities", or you can draw some other probability distribution in the table's graphic editing window. (The predetermined probabilities have all been chosen so that they add up to 100, so that the values can be thought of as percentages, but they really are meaningful relative to each other, and don't have to add up to 100.) The metro object sends bang messages to the table at a rate of 12.5 per second (once every 80 milliseconds) to make a probabilistic choice. The table object responds by sending out an index number from 0 to 5 each time based on the stored probabilities.
Those numbers are in turn treated as indices to look up the desired color and pitch events. The colors are stored in a coll object and the pitch classes are stored in another table object. This illustrates two different uses of table objects; one is used as a probability vector, and the other is used as a lookup array. The pitch choices are just stored as pitch classes 2 6 9 1 4 7 (D F# A C# E G), and those are added to the constant number 60 to transpose them into the middle octave of the piano. The color choices are stored as RGB values representing Red Magenta Blue Cyan Green Yellow, and those are drawn as vertical colored lines moving progressively from left to right. In this way one sees the distribution of probabilistic decisions as a field of colored lines, and one hears it as a sort of harmonic sonority.
The metro object, in addition to triggering a probabilistic choice in the table object, triggers the counter object to send out a number progressing from 0 to 99 indicating the horizontal offset of the colored line. That number is packed together with the color information from the coll, for use in a linesegment drawing instruction for the lcd.
Now that we've seen an explanation of discrete probability distribution, and seen how it can be implemented in a program, and seen a very simple example of how it can be applied, let's make some crucial observations about this method of decision making.
1) This technique allows us to describe a statistical distribution that characterizes a body of choices, but each individual choice is still arbitrary within those constrictions.
2) The choices are not only arbitrarily made, they produce abstract events (index numbers) that could potentially refer to anything. The actual pitch and color event possibilities were chosen carefully by the programmer to create specific sets of distinct possibilities, and the probability distributions were designed to highlight certain relationships inherent in those sets. Theoretically, though, the method of selection and the content are independent; choices are made to fulfill a statistical imperative, potentially with no regard to the eventual content of the events that those numbers will trigger.
3) Each individual choice is made ignorant of what has come before, thus there is no control over the transition from one choice to the next, thus there is no controlled sense of melody or contour in the pitch choices (other than the constraints imposed by the limited number of possibilities), nor pattern to the juxtaposition of colors. This limitation can be addressed by using a matrix of transition probabilities, known as a Markov chain, which will be demonstrated in another lesson.
4) The transitions from one probability distribution to another are all sudden rather than nuanced or gradual. This can be addressed by interpolating between distributions, which will also be demonstrated in another lesson.
5) Decision making in this example, as in most of the previous examples, is applied to only one parameter -- color in the visual domain and pitch class in the musical domain. Obviously a more interesting aesthetic result can be achieved by varying a greater number of parameters, either systematically or probabilistically. Synchronous decision making applied to many parameters at once can lead to interesting musical and visual results. This, too, is a topic for a future lesson.